FinOps in Action: Reduce Google Cloud Costs Through Scheduled VM Shutdown After a Lift and Shift Migration
TL;DR: Unexpected costs can arise from lift-and-shift migrations to Google Cloud. Discover the key considerations to properly automate VM shutdowns during off-hours with Cloud Workflows, manage application dependencies, and dramatically lower your GCP expenses.
🚚 Lift & Shift migrations
Lift & shift is a cloud migration strategy where you move applications and workloads from your source, usually on-premises data center, to the cloud without significantly redesigning them. This approach is often chosen for speed and simplicity, allowing for a quick transition to the cloud. However, it may not fully optimize cloud resources and can lead to higher costs if not managed effectively.
Indeed, when you lift & shift, you might bring along inefficient configurations or practices that were fine on-premises but don’t translate well to a cloud environment (More on them later in the article).
Think of it like moving into a new, modern apartment with all your old, bulky furniture — it might fit, but it won’t necessarily make the best use of the space.
Such practices usually reflect to unexpected cloud monthly costs, so how can we identify the causes of them? That’s where the principles of FinOps join the game.
⚠ Keep it in mind: The idea that “the cloud is always cheaper” is a myth! The cloud offers incredible opportunities, but realizing cost savings requires a shift in mindset and proactive management of the resources.
💰 FinOps overview
FinOps is a collaborative framework for managing cloud costs, that brings together technology, finance, and business teams to make data-driven decisions about cloud usage.
It can be seen as a continuous cycle with three distinct phases:
- Inform: This phase focuses on gaining visibility into cloud spending. It involves understanding current costs, identifying cost drivers, and allocating expenses effectively.
- Optimize: Once you have a good understanding of your cloud spending, it’s time to optimize. This phase involves identifying opportunities to reduce waste, right-size resources, and leverage discounts.
- Operate: The operate phase is about continuous improvement and operational excellence. It involves setting budgets, forecasting cloud costs, and automating processes to ensure ongoing cost optimization.
🤖 Reduce cloud costs by automation
Embracing FinOps means understanding where your money is going and identifying opportunities to not just save, but also reinvest those savings into value-generating activities. Adopting FinOps isn’t always easy; it takes time and iteration. Automation is a powerful enabler, accelerating this transition across all three FinOps phases:
- Inform (Analyze): Automation helps you gain visibility into cloud spending patterns — which VMs are used, when, and for how long. This “Analyze” phase mirrors FinOps’ “Inform” phase, providing deep insights into resource utilization.
- Optimize (Develop): With the knowledge acquired from the previous phase, we move to the “Develop” phase, where we design and build automations to actively address inefficiencies and reduce resource usage.
- Operate (Scale): We make our automations reliable, adaptable, and readily available to other teams, ensuring long-term cost efficiency.

🔍 Analyze the result of your Lift&Shift
How cloud cost is calculated
Cloud costs are dynamic and ever-changing, reflecting the flexible nature of cloud services. Unlike traditional IT infrastructure with its fixed upfront costs, cloud computing operates mostly on a pay-as-you-go model. This means you only pay for the resources you consume for the time you use them. At its simplest form, the cost for each cloud resource can be calculated as Usage ⋅ Rate - Discounts.
This highlights the key factors:
- Resource Usage: The amount of compute, storage, network and other resources consumed.
- Resource Rate: The price per unit of resource, which varies by region, instance type, etc.
- Discounts: Committed use discount, Sustained use discounts, reserved instances, or enterprise agreements.
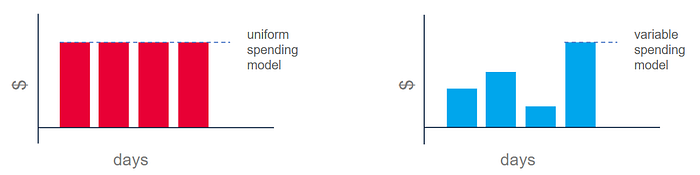
Uniform vs Variable spending model
After a Lift&Shift, organizations often expect stable cloud costs, similar to their on-premises experience. But that’s a misconception. Why?
Traditional data centers involve fixed expenses (hardware, licenses) — a consistent monthly cost regardless of usage. This is a uniform spending model. It’s predictable but inflexible; scaling up requires investment of time and money.
The cloud, however, operates on a variable spending model. Costs fluctuate based on your resource consumption. Use more, pay more; use less, pay less. It’s like your electricity bill.
If you lift & shift without optimizing for the cloud, you’ll likely overspend. You’re bringing old habits — like running servers 24/7 — that are costly in a pay-as-you-go environment. This is a prime example of where automation can help.
Step 1 — Classify saving initiatives
The first step is to gather usage data. Google Cloud Monitoring is an excellent starting point to analyze VM utilization. Its APIs provide the data to answer questions like the followings:
- What’s the average CPU/RAM usage over the month?
- What’s the peak CPU/RAM usage, and when did it occur?
- What percentage of the month did CPU/RAM utilization remain below 30%?
- Are there any usage patterns (e.g., lower usage at night or on weekends)?
Step 2 — Check if you are facing some of the common problems you may encounter after a Lift & Shift migration
Analyzing your usage data will likely reveal three key cost-savings opportunities:
- Unused VMs: Machines that are no longer needed. This is often the quickest win.
- Oversized VMs: VMs with consistently low CPU and RAM usage (e.g., under 30%) are prime candidates for right-sizing.
- Idle VMs in Non-Production Environments: Development and testing environments often don’t need to run 24/7. Shutting down these VMs during nights and weekends can lead to significant savings.
We’ll focus on this last initiative — automating VM shutdowns — as it can often reduce your Google Cloud bill by 15–30%!
🔨 Develop the automation
Understand how to handle application dependencies
Shutting down or starting VMs without understanding application dependencies is risky, as applications often consist of multiple interconnected services. Indeed, a proper startup/shutdown plan requires collaboration with developers to identify applications, their components, and, crucially, their dependencies. Shutdowns are often simpler and can be done in parallel, but startups are critical and usually done sequentially. Many applications fail if they can’t reach dependent services (like a database).
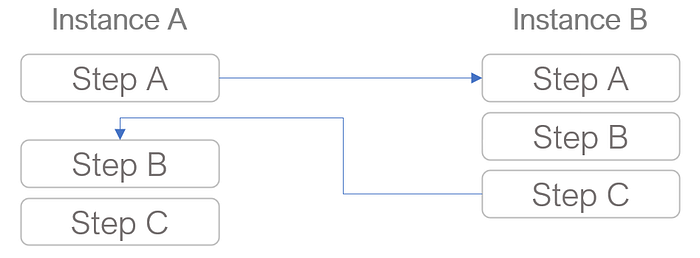
This introduces a key challenge:
If application B relies on application A, you must ensure A is fully operational before starting B.
Let’s explore three mechanisms that can potentially address this, from the simplest to the most complex:
- Time-Based Wait: The simplest approach is to wait a predetermined amount of time. If you know application A typically takes n seconds to start (by observing past data), you can configure your automation to wait at least n seconds after the startup of A before starting B. This is useful when there’s no direct way to check readiness.
- HTTP Health Checks: If application A exposes an API with a health endpoint, your automation can poll that endpoint until it receives a success response (e.g., HTTP 200 OK).
- Guest Attributes (for Complex Interdependencies): Consider a scenario where the startup of the application A requires multiple steps, some of which depend on commands running during the startup of the application B. You might run command 1 on A, then three commands on B, and then continue with commands 2 and 3 on A. In this case, you can use Compute Engine’s metadata server and guest attributes to query the state of an application from another VM before to proceed with the next steps.
Automation flow
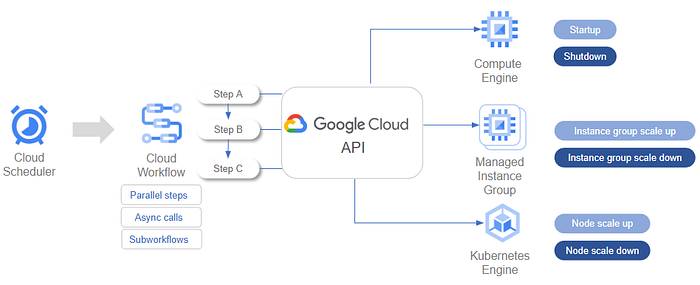
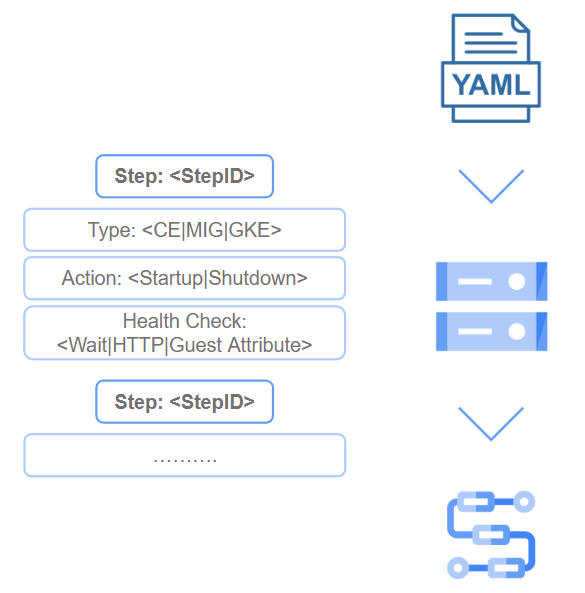
Now that we’ve identified the applications we want to shutdown and understood the dependences among them, then we can define the automation process as a sequence of steps, each interacting with a compute service (e.g., Virtual Machines, Managed Instance Groups, GKE Clusters), and since we have to respect application dependencies, these steps must be executed in a specific order. This requires robust orchestration, and Google Cloud Workflows is perfectly suited for this, allowing us to orchestrate Google Cloud APIs, define conditions, loops, and even parallel steps.
What is Google Cloud Workflows? It’s a fully managed, serverless orchestration platform that allows you to connect and coordinate Google Cloud services and APIs. Workflow is a visual workflow designer where you can define a series of steps, handle errors, set up retries, and even execute steps in parallel. Workflows uses a YAML-based definition language, making it easy to define complex logic in a declarative way.
As a whole, that’s how you can structure your end-to-end process:
Extra: Shutdown of VMs on Google Cloud
While startup scripts reliably execute all defined steps, shutdown scripts don’t offer the same guarantee on Google Cloud. Google Cloud doesn’t ensure that a VM shutdown command will wait for the entire script to complete. This is a crucial point because improperly shut down applications can lead to data corruption, inconsistencies, or incomplete transactions. As the Google Cloud documentation states:
“If your scripts take longer than the time it takes for the instance to stop, then Compute Engine forcefully stops the scripts, which can lead to data loss or incomplete tasks.”
To ensure graceful shutdowns, we need a way to execute commands inside the VM before initiating the platform-level shutdown command. Simply relying on a shutdown script attached to the VM is insufficient. One robust solution is to leverage Cloud Build private pools in conjunction with Cloud Workflows:
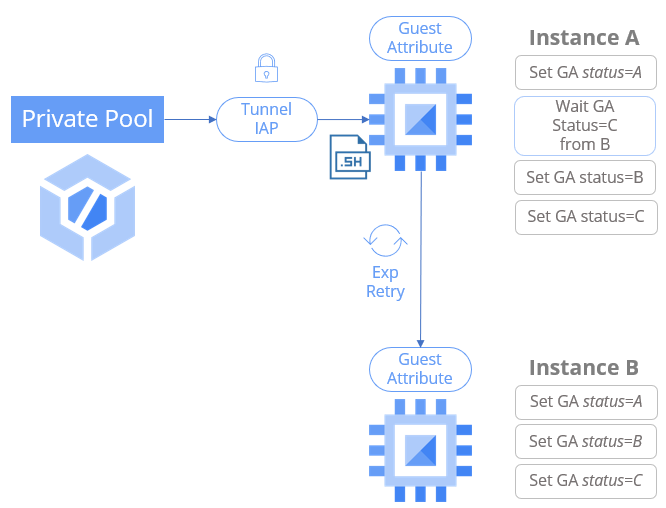
How it works:
- Cloud Build is triggered by Cloud Workflow.
- Cloud Build, using a private pool with network connectivity to your VPC, establishes a secure connection to the target VM via Identity-Aware Proxy (IAP) tunneling. This avoids exposing the VM publicly.
- Cloud Build executes the pre-shutdown commands inside the VM. This might involve gracefully stopping application processes, flushing buffers, closing database connections, etc. — all the necessary steps for a clean application shutdown.
- Cloud Build waits for confirmation that the in-VM shutdown commands have completed successfully.
- Only after successful confirmation Cloud Workflow issue the
gcloud compute instances stopcommand (actually the equivalent API call) to shut down the VM at the platform level.
📈 Scaling the Automation: From One-Off to Enterprise-Ready
The initial automation is valuable, but its true power comes from scaling it across the organization. This means making it reusable, adaptable, and easy to deploy for different teams and a variety of application stacks. We achieve this by moving from a hard-coded solution to a configuration-driven approach.
YAML Configuration: The Key to Flexibility
Instead of hardcoding the steps within the Cloud Workflow definition, we used a YAML configuration file. This allows teams to easily configure the automation for their specific needs without modifying the core workflow logic. The configuration file consists of a list of steps, each with a unique ID, as showed in the example below:
steps:
- id: start_db
service_type: Compute Engine
instance_name: my-database-vm
action: startup
project_id: my-project
zone: us-central1-a
dependency_check: time_based_wait
wait_seconds: 60
- id: start_app_server
service_type: Managed Instance Group
group_name: my-app-server-mig
action: startup
project_id: my-project
region: us-central1
dependency_check: http_health_check
health_check_url: http://my-app-server-mig.example.com/health
dependencies: [start_db]Benefits of this Approach:
- Reusability: The same Cloud Workflow can be used for multiple application stacks, simply by providing different YAML configuration files.
- Maintainability: Changes to the startup/shutdown process for a specific application stack only require modifying the YAML file, not the workflow itself.
- Version Control: The YAML files can be stored in a version control system (like Git).
- Self-Service: Teams can manage their own startup/shutdown configurations without needing to be experts in Cloud Workflows.
- Standardization: Enforces a consistent approach to managing VM lifecycles across the organization.
Conclusions
To recap, don’t let idle resources drain your cloud budget. Start by analyzing your VM utilization patterns, implement an automation strategy using whichever tool/framework you like most, mine are Cloud Workflows, Cloud Build, a configuration-driven approach and the FinOps culture.
The savings — and the improved operational efficiency — are well worth the effort. Consider starting small, with a single application stack, and then gradually scale the automation across your organization.
Hope you found this article useful, don’t hesitate to contact me if you have doubts.

