Featured
BigQuery’s Ridiculous Pricing Model Cost Us $10,000 in Just 22 Seconds!!!

Yes, you read that right. $10,000 burned in less than half a minute.
Not because of inefficient queries. Not because of high compute usage. But because of a completely absurd pricing model that most engineers don’t even realize exists.
If you use BigQuery, there’s a good chance you’re bleeding money without knowing it.
The Setup: A Simple Query — Or So We Thought
Last month, we were helping a customer build a data pipeline. Nothing complicated — just a basic data sampling task from a large public table. Given the dataset’s size, we took precautions:
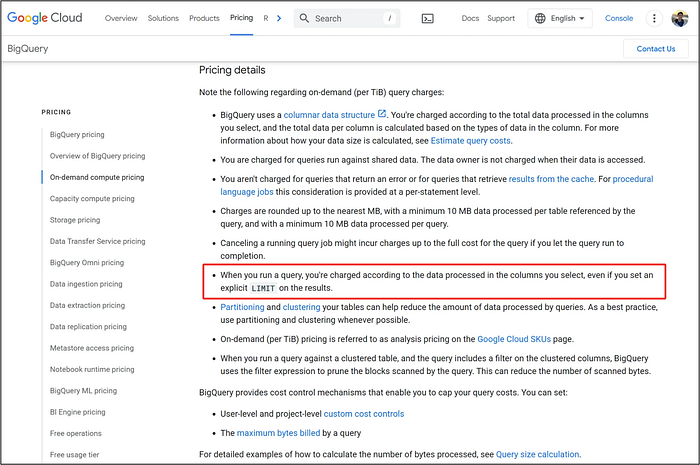
- Used a
LIMITstatement to restrict the result to 100K rows - Query executed instantly—nothing seemed off
- Ran the query three times
The detailed query is:
EXPORT DATA
OPTIONS (
uri = 'gs://xxxxx/*.json',
format = 'JSON',
overwrite = true)
AS (
SELECT *
FROM `bigquery-public-data.crypto_solana_xxxxx.Instructions`
LIMIT 1000000
);This query exports 1,000,000 rows from the Instructions table in the crypto_solana dataset (hosted in BigQuery's public datasets) to a Google Cloud Storage bucket in JSON format.
The invoice arrived: $9,847.24 for Three Queries?!
🔥🔥 BigQuery charged us nearly $10,000. 🔥🔥
🔥🔥 Three queries. 1,576.56 TB of data “scanned.” 🔥🔥


How is this even possible?!
The cost breakdown was even crazier:
- Total “scanned” data: 1,576.56 TB across three queries
- Each query, despite using
LIMIT, was billed for 509.89 TB of scanned data - Queries ran in 22 seconds — which implies a 23 TB per second scan rate
We were completely speechless.
The Discovery: BigQuery’s Hidden Pricing Model
BigQuery is one of the most advanced cloud data warehouses. It has some of the best query optimization in the industry. There is no way it actually scanned 509 TB of data just to return 100K rows for a limit query.
So what was going on?
After consulting friends at Google, we uncovered the trap:
BigQuery doesn’t charge based on processed data — it charges based on referenced data!!!
Read that again.
If your query touches a 1 PB table, even if it only returns a few MB, BigQuery still charges you as if you scanned the entire 1 PB.
This is completely different from how other cloud data warehouses handle queries.
How It Works in Other Data Warehouses
To understand just how insane BigQuery’s pricing model is, let’s compare how LIMIT behaves in Redshift, Snowflake, and Databricks.
Modern cloud data warehouses like AWS Redshift, Snowflake, and Databricks take advantage of columnar storage and predicate pushdown:
- Columnar Storage: Only relevant columns are read, minimizing scanned data.
- Predicate Pushdown: Filtering conditions (
LIMIT,WHERE) are applied as early as possible in query execution. - Partition Pruning: If the table is partitioned (e.g., by date), only relevant partitions are scanned.
For example, in Redshift, Snowflake, and Databricks, if you run:
SELECT * FROM huge_table LIMIT 100;- The system retrieves 100 rows and stops, reducing compute costs.
- Only the necessary data is scanned, and costs reflect actual usage.
BigQuery, however, follows a completely different approach:
- Charges are based on total referenced data, not actual scanned data.
- LIMIT does not reduce the amount of data billed — if your query touches a large table, you’re billed for the entire thing.
- Partition pruning is unpredictable — queries may still scan and bill for full table sizes.
For example, running this query:
SELECT * FROM huge_table LIMIT 100;- Even if only 100 rows are returned, you’re charged as if you scanned the entire table.
- If the table is 1 PB in size, you’re billed for 1 PB of data scanned.
- Filtering doesn’t help — if you reference the table, you pay for it.
A Nightmare for Engineers
Query optimization in BigQuery doesn’t work the way you’d expect. Unlike other major cloud data warehouses, traditional techniques like LIMIT don’t necessarily lower costs. A query that executes in milliseconds can still rack up an outrageous bill.
This goes against common sense — every other major cloud vendor charges based on the actual data processed, not the total table referenced. But in BigQuery, billing is tied to the full dataset touched by your query, forcing engineers to rethink cost calculations in an unintuitive way.
The result? You can burn through cloud credits in no time. Many teams assume GCP’s free credits will last for months, only to find out the hard way that a single bad query can drain them overnight.
Cloud Pricing: A Trap Hiding in Plain Sight
BigQuery is just one example. Cloud providers love to lure users in with “low-cost” pricing models, only to introduce hidden fees.
- Storage is cheap. Compute is expensive.
- Advertised costs are per-TB scanned, but “scanned” doesn’t mean what you think.
- Cloud vendors count on engineers not reading the fine print.
This is why companies often experience unexpected cloud bills — pricing models are designed to be misleading.
Final Thoughts
If you use BigQuery, check your billing reports immediately. To avoid falling into cloud pricing traps, consider:
- Exploring cost-effective alternatives like Redshift, Snowflake, or Databricks
- Using open formats like Iceberg to prevent vendor lock-in
- Running cost simulations before scaling up queries
This isn’t a one-time mistake. It’s a fundamental flaw in BigQuery’s pricing model.
If you’re running large-scale data workloads, you need to understand exactly how you’re being billed — because the cloud doesn’t always charge the way you’d expect.

