BigQuery Cost Optimization with slot management
Data warehousing is the backbone of modern-day analytics, enabling enterprises to store vast amounts of data and unlock insights. One such and widely used across enterprises is Google BigQuery. Google BigQuery is a serverless, fully managed data warehouse on Google Cloud Platform, that simplifies data processing and storage at scale. However, as organizations scale and as the data volume increases, costs can quickly start surging— primarily driven by compute and storage. While storage costs are relatively easier to reduce, compute costs tied to slot usage can be a major expense. Reducing the compute cost can be trickier and needs a deeper understanding of the entire ecosystem and making some careful decisions.
So, in this blog, we will focus on cost optimization through BigQuery slot management.
What are slots?
Slotsare simply BigQuery’s computational units — some CPU and memory. When you run a query in BigQuery, it splits it into stages, and each stage is processed using a certain number of slots. The sum of all slots consumed by the stages becomes the total slots required by the BQ job.
Note: It is always good to convert slot milliseconds to slot hours for better understanding. For example, the below job consumed 0.02 slots (88096/1000/3600)

BigQuery cost models:
- On-demand model: Pay-per-query, where BigQuery automatically provisions slots. The cost is associated with how much data you query scans. The current cost is around $6.25/TB of data scanned. There is no guarantee of how many slots.
- Capacity-based model: Purchase dedicated slots on a monthly or yearly basis for predictable workloads. This is cheaper and has special discounts associated with it. This is like you purchase the slots, pay once, and use as much as you want.
Enterprises prefer the
Capacity-basedmodel as it is much cheaper and the workload is predictive. The on-demand model is suitable for exploring and initial testing purposes.

Now that we understand the basics of slots, let's dive deep into ways of saving costs on BigQuery compute. An effective slot management strategy can significantly reduce costs without compromising data warehouse performance. By understanding and fine-tuning slot usage, enterprises can optimize query performance, handle spikes gracefully, and balance cost efficiency with business needs. We will dive into practical strategies for slot management, including commitment discounts, using the BigQuery Slot Estimator, fine-tuning SQL queries by handling partition skew and high-cardinality joins, leveraging flex slots, and setting up monitoring to maintain control over your compute resources.
Slot Commitments:
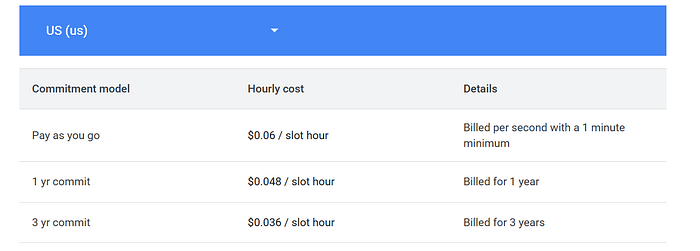
This is the most basic and straightforward way. This is simply getting discounts from Google. Let us understand this section with an example.
- Slots are purchased at the Google organization level.
- A reservation project is created and is tied to the organization’s billing account.
- Say 1000 slots are purchased in the reservation project. There are SKUs in which you purchase these 1000 slots. Let's not dive into SKUs. The better the SKU, the higher the benefits, and the higher the cost for 1 slot.
- You can get a monthly, 1-year, or 3-year commitment, the higher the period the more the discount.
- Note, that once you purchase commitment plans, you are bound to pay that cost. So for example, if you purchase a commitment for 1 year, you will have to pay the 1 year cost of 1000 slots, whether you use it or not.
Slot Allocation:
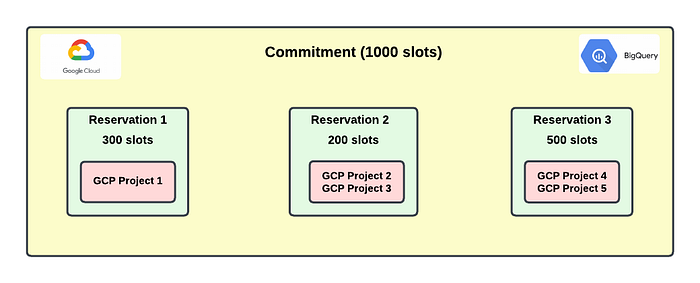
Once the slots are purchased, effectively assigning them to projects is a challenging task. Slots are assigned to a reservation. Each reservation can have more than 1 assignment for the GCP project. Projects within the reservation share the baseline slots allotted to the reservation. Reservations under the same organization can share the idle slots amongst themselves.
Rule of thumb:
Slots allocated to a reservation are consumed in the following fashion:
- Baseline slots are 1st consumed by the jobs running in the reservation
- Once the baseline slots are exhausted, idle slots from other reservations are borrowed
- If idle slots are also not available, then the reservation will autoscale if configured to autoscale
- Still, if the jobs need more slots, it will start throttling until more slots are available in the pool
— Baseline/Idle slots cost is the same as committed slots (cheaper)
— Autoscaling slots and uncommitted slots are expensive and follow Pay-as-you-go (PAYG) cost (expensive)
Monitoring slot usage
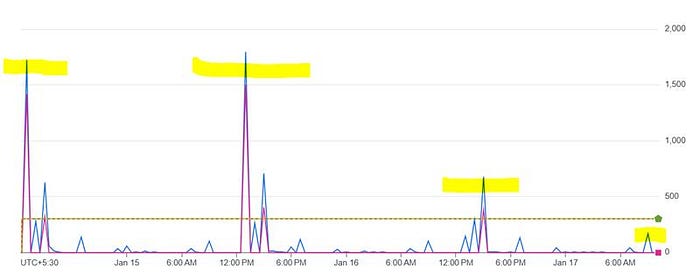
A very important task when it comes to slot management. Google provides out-of-the-box solutions to monitor the slot usage of each reservation. We can select the time frame to check slot usage during a particular period of the dag, check for average slot utilization, P100, P99th slot usage, etc. The monitoring dashboard gives a very good idea if a particular reservation is overprovisioned or underprovisioned with slots. Let's look at an example below.
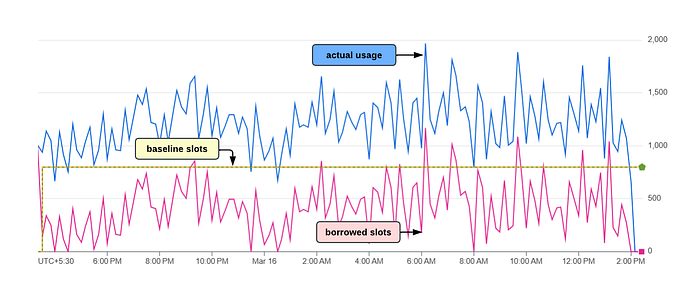
The graph shows slot usage for a reservation. The reservation has 1000 baseline (guaranteed) slots. During the day, there are more than thousands of BigQuery jobs that are run periodically in the project. It's important to understand that each BQ job consumes a certain amount of slots and once done they release the slots back. As per the graph, the 1000 baseline slots are completely used up by the project, while it borrows idle slots from other reservations of the organization to fulfill its slot requirements.
In the 1st glance, it may look like, 1000 baseline slots aren't enough for this reservation as the actual usage is always above 1000. However, jobs in this reservation have never faced slot contention. We will check the reason in the below topic.
Slot Estimator
Honestly, one of my personal favorite sections when it comes to BQ cost optimization. This section can answer a lot of hidden questions. This gives the best insights into how your BQ jobs are performing inside a reservation. Slot estimator is also an out-of-the-box solution offered by Google.
Let us understand this in-depth and how to make a decision:
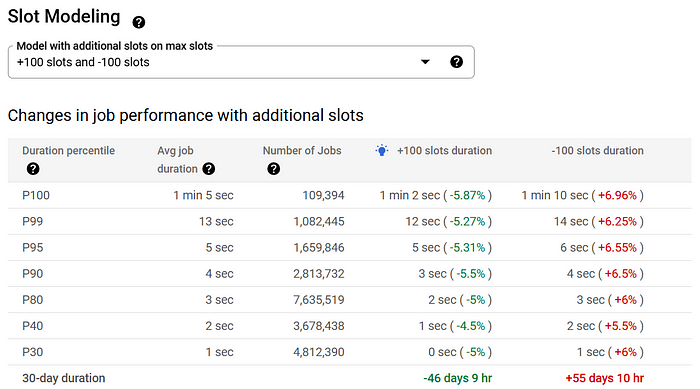
- Google slot modeling takes into consideration 30 days of past data and does the analysis
- With 1000 baseline slots and the idle slots it can borrow, the slot modeling shows the impact on the job performance if we increase or decrease the number of baseline slots.
- P100, and P99 are the most crucial metrics. Google slot modeling bifurcates all the jobs running in the reservation into P100, P99, etc buckets based on job duration.
- We can say that P100 are most time-consuming, slot-consuming query followed by P99.
- Hence, increasing or decreasing 100 slots will marginally affect the performance of the queries especially in P100 and P99. A difference of 8 seconds for P100 and just 2 seconds for P99.
- Hence, depending on how crucial and time-sensitive your jobs are, we can decide to increase or decrease the slots for the reservation.
- In my case at least, the jobs in the reservation aren't very time-sensitive and highly crucial. Hence, if I weigh the cost of an additional 100 slots vs the performance improvement, I prefer not to increase the slots as the current performance is optimal for my use case.
- This decision may be the opposite if you have mission-critical jobs that are time-sensitive. In such cases, adding slots makes more sense to get the desired performance.
But now the question is, what are these P100, and P99 time-consuming jobs? Can we identify their SQL query and improve their performance without adding more slots? Let's check that next.
BigQuery Job Forensics:
As discussed, the P100, and P99 jobs mostly belong to time and slot-consuming queries. An unoptimized SQL can consume exceptionally higher slots putting pressure on your reservation. Whenever a job gets executed, it generates a BigQuery Job ID. Further checking the Job ID in the job explorer will show how many slots it consumed with some Query Insighsts. You can also use the query execution graph to get performance insights for queries. Query insights provide best-effort suggestions to help you improve query performance.
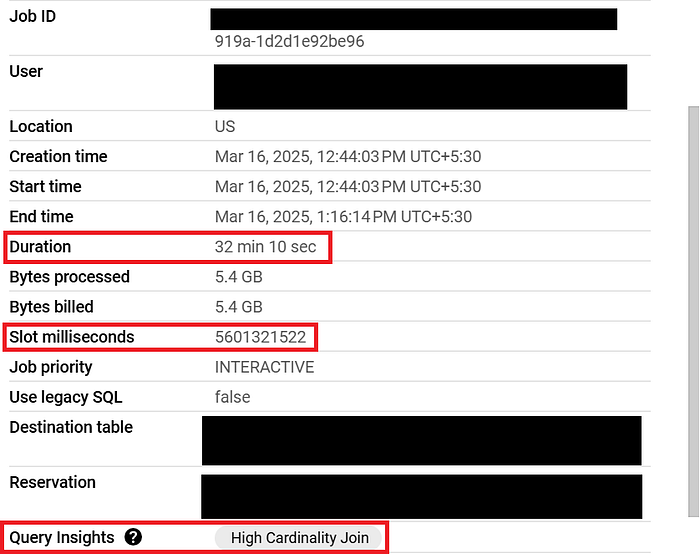
Learnings from job insights:
- From the above example, we can see the job took 32min to execute which is very high as it just processed 5.4GB of data
- The job consumed 1555 slots (5601321522/1000/3600). Note slots are always calculated as slot hours.
- The query insights says it is a High Cardinality Join, which means, the JOIN logic isn't very optimized in the query. Fixing the JOIN logic may help reduce the slot consumption and the query will be executed in less time.
Frequency of slot-eating queries
Consider this scenario. A query that runs every 1 hrs (24 times a day) and consumes 200 slots each run vs a query that runs twice a day and consumes 2000 slots each run. Both scenarios are harmful as they will put immense pressure on the reservation’s slots. It is important to catch all types of queries with significant slots based on their frequency of execution. We can query the INFORMATION_SCHEMA which will list the top slot-consuming queries along with their frequency.
WITH query_summary AS (
SELECT
query,
COUNT(*) AS execution_count,
SUM(total_slot_ms / 1000 / 3600) AS total_slots, -- Total slots hours
ARRAY_AGG(STRUCT(job_id, parent_job_id) ORDER BY creation_time DESC)[OFFSET(0)] AS latest_job_details, -- Latest job details
user_email
FROM `GCP_PROJECT_ID`.`region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
EXTRACT(DATE FROM creation_time) = CURRENT_DATE() - 1 -- Jobs that ran a day before
AND query IS NOT NULL
)
SELECT
query,
execution_count,
(total_slots / execution_count) AS avg_slots_per_execution, -- Average slots per execution
total_slots,
latest_job_details.job_id AS latest_job_id, -- Latest job ID
latest_job_details.parent_job_id AS latest_parent_job_id, -- Parent job ID of the latest job
user_email
FROM query_summary
ORDER BY total_slots DESC, execution_count DESC
LIMIT 50;Output:
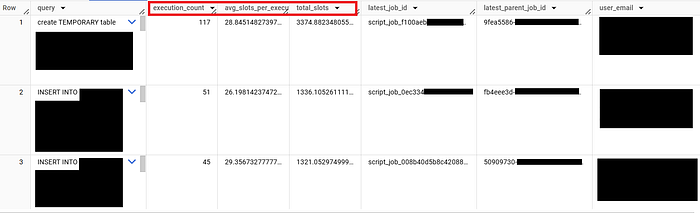
This query will help find all the Job IDs that consume most of the slots of the reservation and allow us to optimize those queries based on the insights. So now the question is how do we optimize the SQL query? Let us see in the next section.
Optimize the SQL query:
Now that we know which queries consume most of the slots, we can work on optimizing those. By far this is the most ideal step i.e. to write the best and clean SQL query. Optimizing the SQL query will help the job run faster and consume fewer slots.
I will list the checklist that we can follow to ensure our jobs are well-optimized and clean.
- Partitioning the tables —
Partitioninghelps improve query performance and reduce costs by allowing queries to scan only relevant partitions instead of the entire table. Ideally, use a timestamp/date column for time-series data. - Clustering the tables —
Clusteringfurther reduces the amount of data scanned by organizing data within each partition based on specific columns, improving query efficiency. Select columns that are frequently used in filtering and sorting for clustering. - Use Materialized Views & BI Engine — Reduce compute cost for repetitive queries.
Materialized Viewsprecompute and store the results of frequently run queries, reducing the need to recompute them each time, thus saving on processing costs.BI Enginespeeds up the dashboard and report performance by caching query results in-memory, reducing the reliance on repeated full scans of BigQuery tables. - Optimize JOINs — Avoid
high-cardinality joins. In my experience, JOINs consume most of the slots, and optimizing the JOIN logic helps improve the performance.
Let's deep dive into some techniques to improve the JOIN logic:
a. Use Partitioned Joins: Ensure both tables are partitioned on the same key to minimize data scanned.
b. Filter Data Before Joining: Reduce the data size scanned by applying filters before performing joins. Use good WHERE clauses.
c. Denormalize Data Where Possible: Pre-aggregate or flatten data to reduce the need for expensive joins.
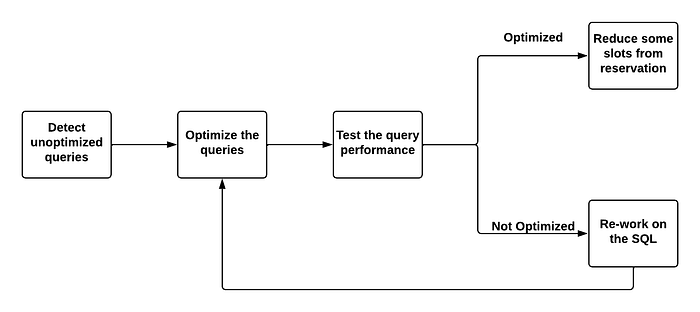
Significant slot consumption can be reduced by following the above techniques. As and when the SQLs are optimized, monitor the slot usage and then gradually you can reduce the slots from the respective project’s reservation.
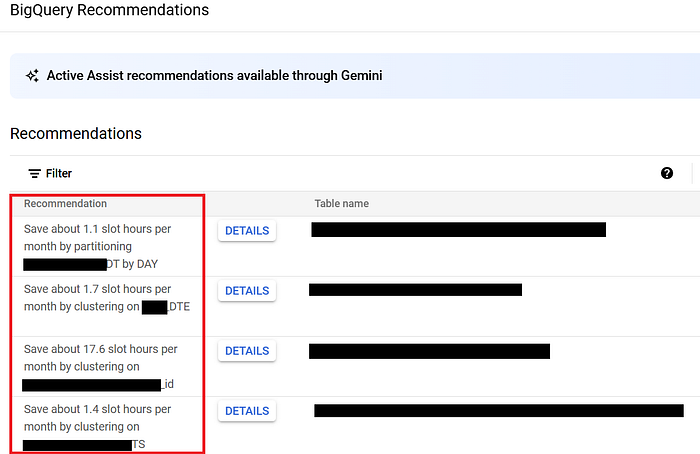
Use Gemini Insights:
You can enable BigQuery Active Assist recommendations that are powered by Google Gemini. The BQ Assist helps with recommendations related to partitions and clustering of tables. It analyses the last 30-day pattern and usage on the tables checks which column has substantial usage and recommends it to be clustered or partitioned.
Handle burst load:
Consider a scenario where you need slots only for a few hours that too during month end for some month-end data processing. Or consider you have a special event coming up and you expect huge traffic spikes for 3–4 days. In all such scenarios, you may want to temporarily provision slots only for those days for a few hours. You may want to spend by making another monthly or annual commitment. In that case flex slots is the way to go. Flex slots are cheaper than non-committed slots while a bit more expensive than slots that are committed. Hence, flex slots are the best option whenever we expect some burst loads and need to add capacity for a minimal time.
You may have enough idle slots than you think !!
Slightly tricky to explain but let's get back to the rule of thumb. Jobs running in a reservation will consume the baseline slots and only once the baseline slots are exhausted it will start borrowing the idle slots from other reservations within the organization.
Remember the fact that:
1. Not all BQ jobs run at the same time and end at the same time
2. BQ jobs once done, they release the slots back to the pool, so other jobs can use those
3. Some reservations may be idle and the BigQuery algorithm evenly distributes the idle slots to the required projects
Hence, idleslots mostly come to the rescue and help your job get done. However, if you see slot contentionas a query insight into your job, then you should consider increasing the baseline capacity of the reservation.
Hence, monitoring the overall slot consumption of each reservation and looking at the slot usage patterns is important.
Some Bonus Tips !!
- Reduce the BigQuery timeout: The default
timeoutfor a BigQuery Job is 6 hours. If a query has issues or errors, or a very poorly written JOIN query, then it will keep running for at most 6 hours, wasting all the slots of the reservation. In such a case, it's better to keep the timeout for the BQ project to 2–3 hours, unless there is an exception. - Keep slot commitments to 100%: If you purchase new slots make sure you
commitit for 1 month or annually to get discounts. Uncommitted slots are charged at a Pay-as-you-go rate, which is the costliest SKU for slots. - Proactive monitoring: Keep
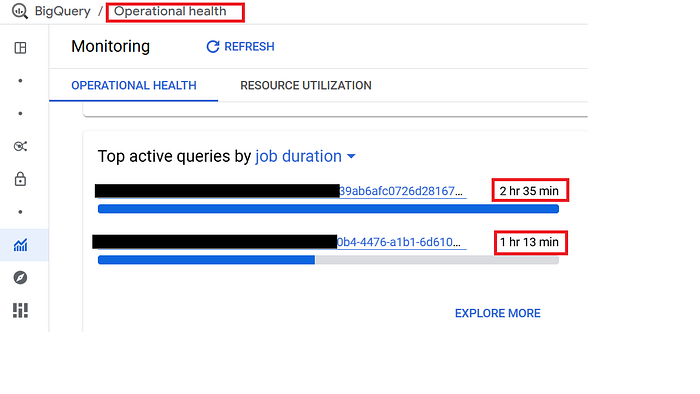
monitoringyour slot usage daily. Key decisions for cost optimization will depend on workload management, adjusting the baseline slots for reservations, checking how many idle slots help to get the jobs done, slot modeling insights, etc. Set upalertson the billing dashboard to get notified about spikes related to BQ compute. - Kill the bad jobs: If you find certain jobs are continuously running for long hours with errors, it is better to
kill/cancelthose jobs to further prevent the wastage of slots. Hence, vigilant monitoring of jobs is required. Google dashboard also shows the long-running queries on the console.
Last but not least, if you ever see a cost spike in BigQuery compute, if you are clueless, it's good to immediately involve Google support through a Google case. Google support can then further deep dive into the organization's projects and find the root cause or the queries that caused the cost spike.
Conclusion:
Managing costs in an enterprise BigQuery data warehouse is critical for long-term sustainability, without sacrificing performance. In this blog, we covered all essential cost-saving techniques, including optimizing slot usage, query performance, and proactive monitoring. While BigQuery offers flexibility and scalability, unoptimized usage can lead to skyrocketing expenses.
A proactive approach to cost savings ensures that you are making the best use of resources while keeping query performance optimal. Striking the right balance between cost efficiency and high performance is key to maximizing the value of BigQuery in an enterprise. By continuously monitoring and optimizing workloads, we can achieve scalable, cost-effective, and high-performing data analytics solutions.
