Build richer gen AI experiences using model endpoint management
Tabatha Lewis-Simo
Product Manager
Bala Narasimhan
Group Product Manager, Google Cloud
Model endpoint management is available on AlloyDB, AlloyDB Omni and Cloud SQL for PostgreSQL.
Model endpoint management helps developers to build new experiences using SQL and provides a flexible interface to call gen AI models running anywhere — right from the database. You can generate embeddings inside the database, perform quality control on your vector search and analyze sentiment in the database, making it easier to monitor results. This feature is available through the google_ml_integration extension, which enables an integration with Vertex AI for both AlloyDB and Cloud SQL for PostgreSQL.
Previously, the google_ml_integration extension only allowed users to call models hosted on the Vertex AI platform. With model endpoint management, you can leverage models running on any platform — including your own local environment. We also added ease-of-use support for models running on Open AI, Hugging Face, and Anthropic, as well as Vertex AI’s latest embedding models so you can easily access these models. We have preconfigured the connectivity details and input/output transformation functions for these providers, so that you can easily register the model and simply set up the authentication details.
For Vertex AI models, we have pre-registered embedding and Gemini models so that you can easily start calling them. Plus, newer embedding models have built-in support meaning you are able to access the latest versions of pre-registered models allowing you to start making prediction calls out-of-the-box.
In this blog, we’ll walk you through three example workflows that leverage model endpoint management to build richer generative AI experiences.
-
Generating embeddings with Open AI embeddings models
-
Leveraging Gemini to evaluate vector search results
-
Running sentiment analysis to analyze user sentiment
First, register your model.
To use your own model, register your model using the create model function, where you specify model endpoint connectivity details. You can then configure a set of optional parameters that allow you to transform the input and output of the model arguments to a format suitable for your database. Here’s an example of registering Anthropic’s Claude model.
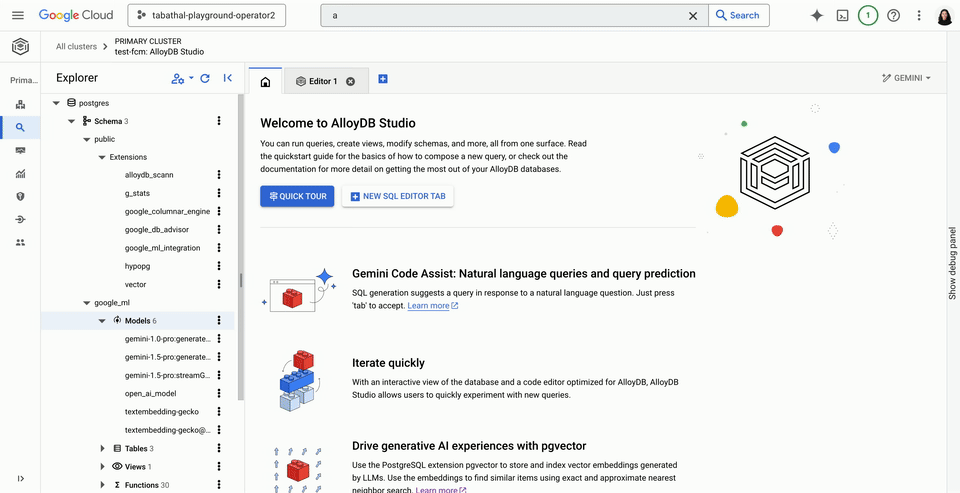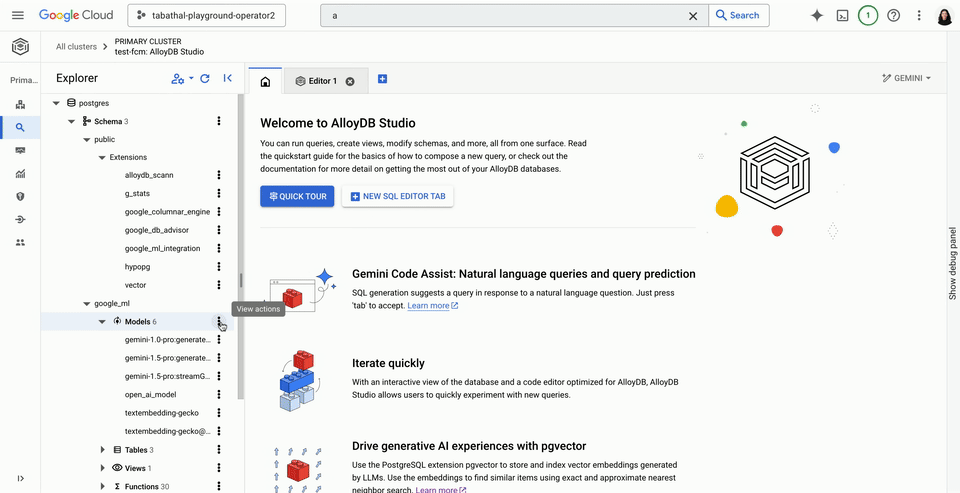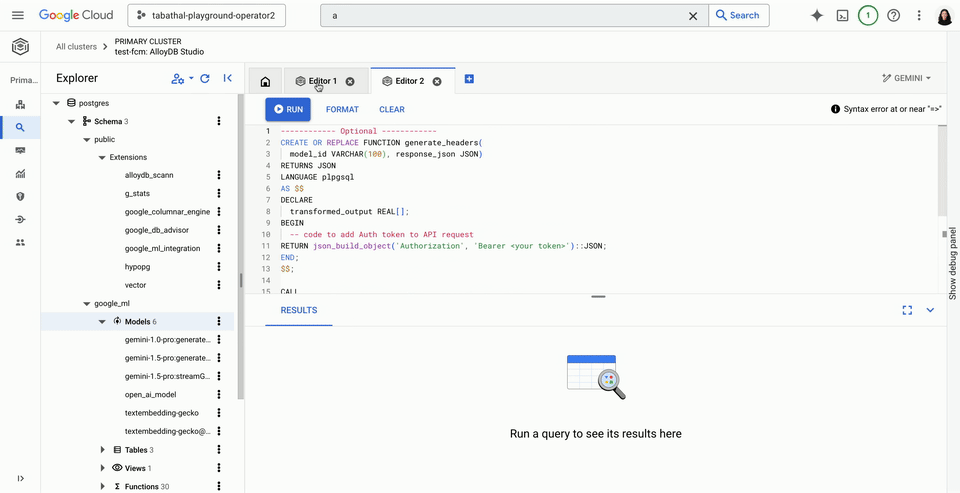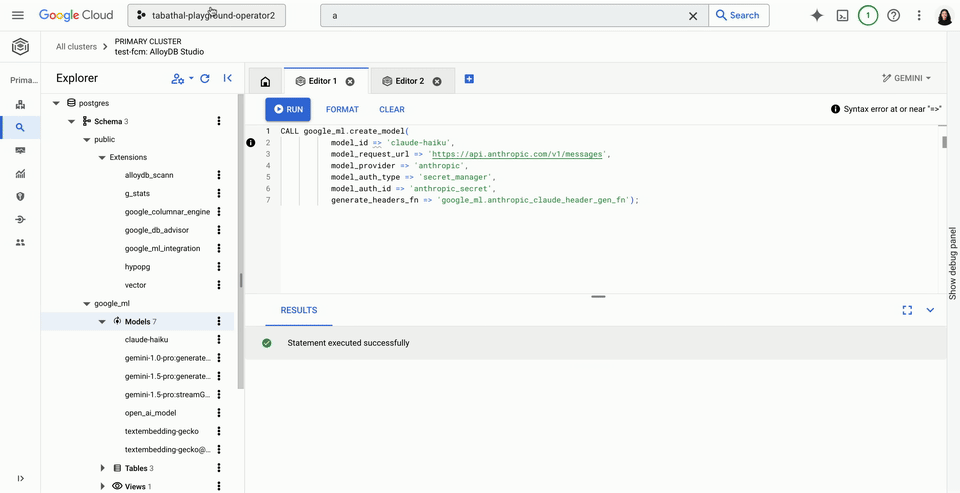
Once you register your model, you can call it with the predict row function for any AI model — or you can use the embedding convenience function to call an embedding model.
#1: Generate embeddings with Open AI embeddings models
Model endpoint management allows you to leverage the embedding convenience function with any embeddings model, even ones that don’t run on Google Cloud. Say you want to generate embeddings with OpenAI’s ada embeddings model. With our ease-of-use support you need only register your authentication credentials, register the model, and start generating embeddings. You first need to configure the authentication for the endpoint you would like to reach — you can do so either by creating a PostgreSQL function to specify your API key in the header of the API call or by creating a secret with secret manager and then registering the secret with model endpoint management.
To register your secret, you simply need to specify the secret path and create an ID for the secret. You can find the secret path in the resource manager by clicking on the secret, and then clicking “copy resource name” on the specific version of the secret you want to use.
Once your secret has been registered, you can register your model and point to the secret, open_ai_secret, when you register the openai-ada model. Our ease-of-use support handles the input and output formatting so that you can generate embeddings from data in your database and directly use the output embedding for vector search.
You then need only specify the name of the model you have registered in the first argument and the text in the second argument. For instance, if you want to generate an embedding on the word “I love Google Databases”, you would invoke the embedding function like so:
If you want to generate an embedding in-line while performing a vector search, combine the embedding function with vector search in SQL using the following syntax:
Model endpoint management also has built in integrations with Vertex AI’s latest embedding models, allowing you to access any of Vertex AI’s supported text embedding models. We recommend the embedding() function for in line SQL queries or to generate stored embeddings on datasets smaller than 100k rows.
#2: Leverage Gemini to evaluate vector search results
In addition to a deep integration with embedding models, model endpoint management provides developers out-of-the-box support for the latest Gemini models. Gemini Pro and Gemini Flash Light are both available as pre-registered models in AlloyDB and Cloud SQL for PostgreSQL. Leveraging Gemini, you can generate content, perform sentiment analysis or analyze the quality of vector search results. Let’s see how you might analyze the quality of your vector search results with Gemini using the predict row function.
Suppose you have a table apparels with an ID, product_description and embedding column. We can use model endpoint management to call Gemini to validate the vector search results by comparing a user's search query against the product descriptions. This allows us to see discrepancies between the user's query and the products returned by the vector search.
We are able to pass in the vector search results to Gemini to evaluate how well the user’s query matches the descriptions qualitatively, and note differences in natural language. This allows you to build quality control to your vector search use case so that your vector search application improves over time. For the full end to end use case follow this code lab.
#3: Run sentiment analysis to analyze user sentiment
One of the benefits of calling Gemini in the database is its versatility. Above, we showed how you can use it to check the quality of your vector search. Now, let’s take a look at how you might use it to analyze the sentiment of users.
Say you are an e-commerce company and you want to perform sentiment analysis on user review information stored in the database. You have a table products which stores the name of the product and their descriptions. You have another table of product reviews, product_reviews, storing user reviews of those products joined on the id of the product. You just added headphones to your online offering and want to see how well they are doing in terms of customer sentiment. You can use Gemini through model endpoint management to analyze the sentiment as positive or negative in the database and view the results as a separate column.
First, create a wrapper function in SQL to send a prompt and the text you want to analyze the sentiment on to Gemini with the predict row function.
Now let’s say you want to analyze the sentiment on a single review — you could do it like so:
You can then generate predictions on only reviews containing the word “headphones” by using a LIKE clause and calling your get sentiment function:
This should output whether the review was “positive, negative or neutral” for user reviews regarding headphones. Allowing you to see what the user sentiment is around this new product. Later, you can use aggregators to see whether the majority of the sentiment is positive or negative.
Get started
Model endpoint management is now available in AlloyDB, AlloyDB Omni and Cloud SQL for PostgreSQL. To get started with it, follow our documentation on AlloyDB and Cloud SQL for PostgreSQL.
